
ViT 正式加入 SSL backbone 大家庭,Facebook 带着 baseline 来了
paper: https://arxiv.org/abs/2104.02057
本文主要工作:
- 提出自监督训练 ViT 的方案 (Contrastive Learning for ViT)
- 探究 ViT 训练不稳定的问题
MoCo v3
没有大改,不是重点
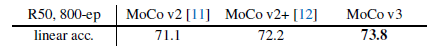
-
改动1:去掉了 memory queue
原因:batch size 足够大 (>4096) 时带来的增益不明显
这一模块本来就是为了计算资源有限的情况设置的,for simplicity,Facebook 不需要(摊手
-
改动2:编码器 $f_q$ 多加了一个 prediction head
$f_q$: backbone + projection head + prediction head
$f_k$: backbone + projection head
ViT 自监督训练过程中的稳定性分析
探究基本训练配置
Batch Size
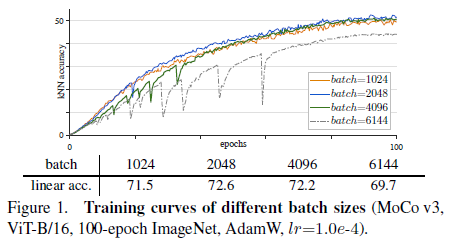
-
结论:batch size > 2048 时训练不稳定的情况愈发明显,会造成性能下降
-
作者分析:训练不稳定可能是由于反复陷入-跳出局部最优解,且
1) 最终结果只是下降了几个点(e.g., 1~3%),没有出现不收敛等明显的退化情况,
2) 用同一训练配置进行多次训练的最终结果相差不大(e.g., 0.1~0.3%),
因此难以察觉
Learning Rate
采用线性缩放规则:$lr=$ baseLr x BatchSize / 256
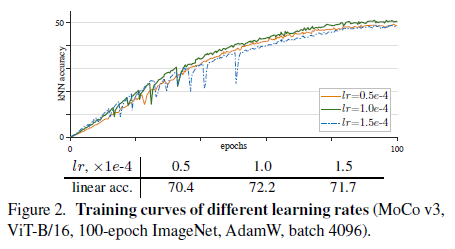
- 结论:lr 小,训练稳定,性能差更多是因为欠拟合;lr 大,训练不稳定,性能更多取决于训练稳定性
Optimizer
对比 AdamW 与 LAMB 优化器 (Fig.2 vs. Fig.3)
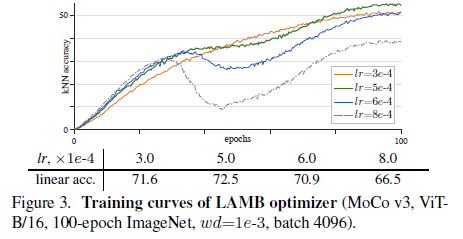
- 结论:
- lr 合适时,二者效果相当
- LAMB 对 lr 更敏感,不合适的 lr 会导致较严重的性能下降
- 为省去 lr search 的麻烦,建议直接用 AdamW
- 作者分析:LAMB 的训练曲线是平滑的,但在中间逐渐发生退化,这可能是由于 LAMB 避免了梯度突变,但不可靠的梯度带来的负面影响会逐步累积
提升训练稳定性的小技巧
-
结论:
-
不训练 ViT 的 patch projection 层(随机初始化后固定)可以提升训练稳定性
实验证明该 trick 对MoCo, BYOL, SwAV 都有效
-
-
其它实验:对 patch projection 层,
1) 使用 BatchNorm (BN), WeightNorm (WN) 对改善训练稳定性没有帮助;
2) 使用足够小的阈值的梯度裁剪 gradient clip 有效,注意到这在极端情况下就是固定该层
-
作者分析:
- 冻结第一层没有改变 ViT 的架构,但缩小了解空间,这表明问题还是出在优化过程上
- 本文提出的 trick 能够缓解训练不稳定的问题,但并没有完全解决,patch projection 层不太可能是训练不稳定的根本原因
- 这个问题涉及到 ViT 的所有层,只因为第一层不是 Transformer,因此容易单独处理
实验结果
训练时间开销
- ViT-B (100ep): ~128 GPU days, ~22.4 TPU days
- ViT-H (300ep): ~625 TPU days == ~1.7 TPU years
不同自监督框架的比较
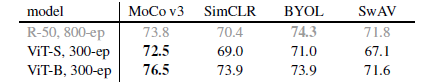
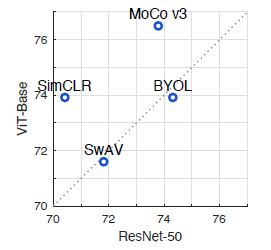
- MoCo v3 用于训练 ViT 效果优于 SimCLR,BYOL,SwAV
- 在 MoCo v3 和 SimCLR 训练框架下,ViT 的训练效果优于 R50
消融实验 (ViT + Moco v3)
Position Embedding
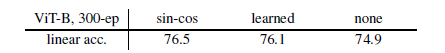
- 作者分析:不使用位置编码性能下降不明显
- 消极的一面:当前的模型还不能有效地利用位置信息
- 积极的一面:ViT 能够仅通过图块 (patches) 学习到强有力的图片表征(representation),且这样的表征具有排列不变性(permutation-invariant)
Class Token
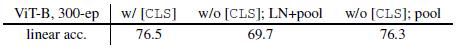
- 结论:额外增加全局token不是必要的,但去掉全局token的同时也要去掉 LN
BatchNorm in MLP heads
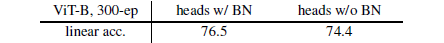
-
结论:去掉 BN 会降低准确率,但模型不会完全崩溃,说明 BN 不是对比学习的必要组件,但合理使用能带来性能提升
实验发现去掉 BN 时,batch size 要减小到 2048,否则不收敛
Prediction head
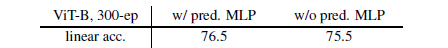
-
结论:
-
预测头不是MoCo的必要组件
在 BYOL 与 SimSiam 等不使用负样本的训练框架中,预测头是必要的
-
其它结论
-
最优动量更新系数 $m=0.99$
-
把 ViT 中 MLP 的 LayerNorm 换成 BatchNorm 能带来 ~1% 的提升
实验发现把 ViT 中所有 LN 换成 BN,即把 Self-Attention 模块中的 LN 也换掉,会造成训练不收敛
-
更小的切块(e.g., 7x7) 增大了计算量(~6x FLOPs),提升了准确率(~2-3%)
-
目前,使用更重量级的 ViT 和 ResNet 模型带来的性能提升都趋向于饱和
作者分析:一种可能的解决办法是使用更大规模的数据集进行训练;但这种饱和也可能是因为现有的基于实例区分的自监督训练方式能力有限,这就需要开发更难且更有效的自监督代理任务
迁移学习

-
作者分析:
-
ViT 对预训练的数据量有一定的要求,train from scratch 效果很差
这说明在数据量不够的情况下,ViT 由于缺乏卷积神经网络具有的归纳偏好,更难学习到有效的表征
-
现有工作在更大规模数据集上进行全监督预训练的ViT,在迁移到下游小数据集时的表现明显优于本文自监督训练的效果
-
下一步工作:follow NLP 的发展轨迹,用重量级模型+大型数据集进行预训练
-